ccqueue: Coding agent task queue
Experimenting with queue-based task systems for Claude Code
View on GitHub ↗What is ccqueue
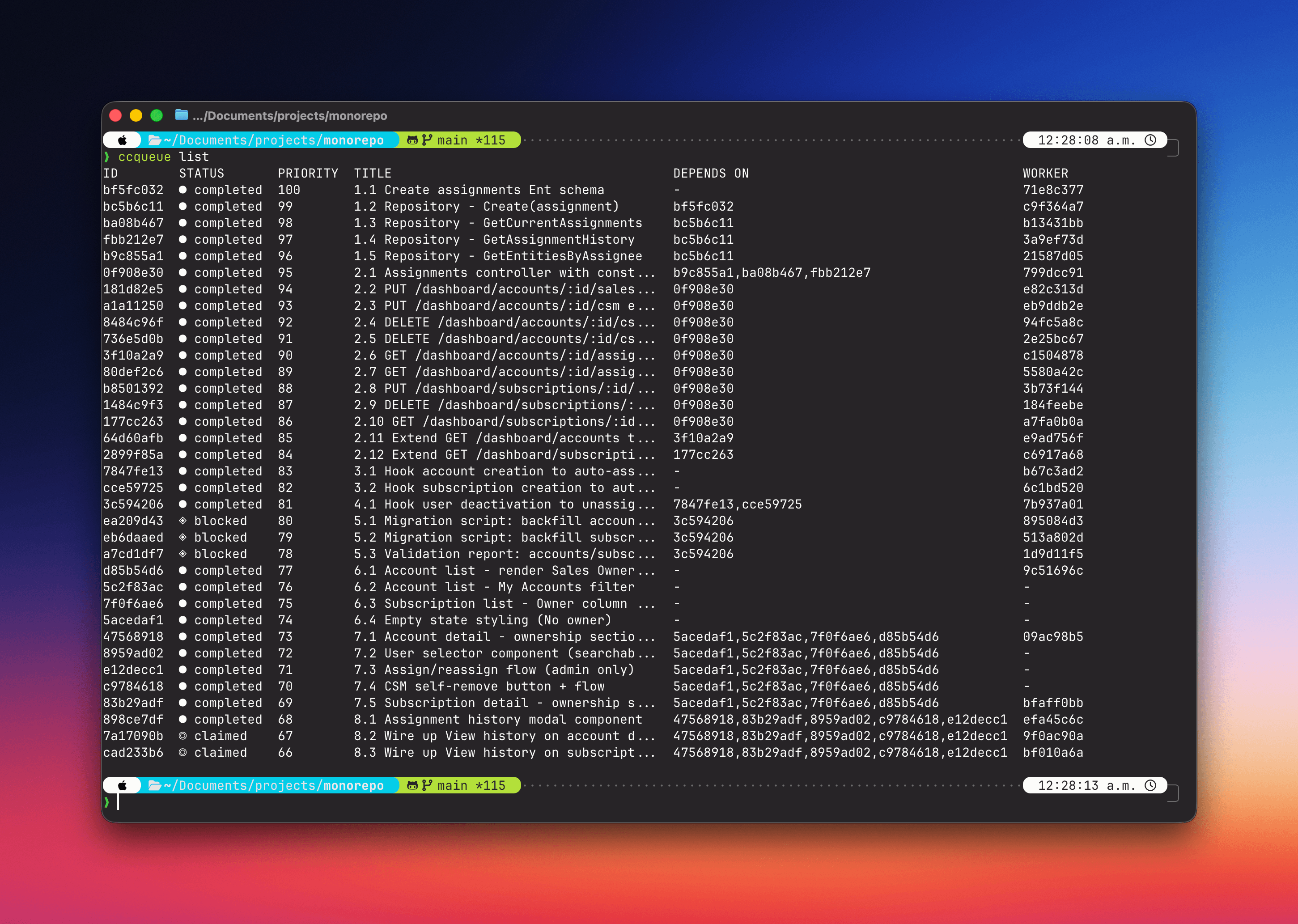
ccqueue was an experiment I ran in December 2025. It was a task system designed to decouple entirely from Claude Code and allow tasks to flow into multiple agents.
Why did I build it
I was running into bottlenecks within my workflow. I would produce a large spec document and break it down into atomic tasks. These tasks I’d then try to get a fleet of agents to pick up, but there would be issues with file read/write contention and babysitting which agents picked up what was tricky. To put it simply, ccqueue stopped 2 agents grabbing the same task, since it was no longer just a file.
At this time, Claude Code did not have a true Tasks system yet, as that was introduced ~3 weeks later. Even when that was produced, it was single-stream per agent instance, not cross instance. As of when I’m writing this, Claude Code still only has a single-stream task system.
I also was noticing far better results from Claude when I would expose it to these checklists. It felt like a major unlock and that I just had to find the right way for Claude to interact, and it would produce results more reliably. This was an experiment to prove that.
Technical details
- Storage was SQLite + markdown, split on purpose. Coordination state lived in SQLite (WAL mode on so multiple agents can read/write at once): task rows, dependency edges, and context requests. The actual task body i.e. the spec, files to touch, acceptance criteria, is a markdown file on disk (~/.ccqueue/tasks/
.md), and the DB row just stores a pointer to it. The DB was for coordination; the markdown was the agent-readable payload. - Had a bit of a state machine for task statuses, so wasn’t really just a pure queue.
- Dependencies operated as a DAG. Stored in memory as a graph. Cycles rejected and completing a task auto-unblocked dependencies in the tree.
- Atomic claiming was done via a SQLite transaction to ensure 1 claim only
- Events were run via an embedded NATS server. All other CLI calls connected as a client and degraded gracefully to DB only, if the daemon wasn’t up.
- 2 skills: coordinator and worker. Coordinator split tasks into atomic levels and populated ccqueue. Workers looped on claim -> read -> work -> update. Nothing special here.
- Had added context requests as a back-channel when the worker agent was unsure, but it was rarely used by the agents at the time.
- Heartbeats were integrated but didn’t really work. They lived in memory, died with the process, so a crashed agent’s task stayed claimed with no reassignment. And this is what led me to build orca.
What were my findings
- Atomicity produced far more reliable results. Better codebase standards following being the prime example.
- Claude presumed similar syntaxes constantly instead of checking docs, e.g. add vs create, remove vs delete
- Structured task template also was a strong driver for better success.
- Claude liked having access to a CLI to execute actions
- Queue based isn’t the best approach when there’s dependencies
- Lacked a good way to pass task context and information, which resulted in centralising the data in other ways such as specs
- Orchestration patterns hard to implement from pure queues
- Needed rewriting if I wanted to support remote or shared storage
- I didn’t actually want a queue. I wanted a dependency-aware orchestrator.